https://spin.atomicobject.com/2014/06/24/gradient-descent-linear-regression/
Go to this link it helps you to understand the overview gradient descent .
Code for this example can be found here
from numpy import *
# y = mx + b
# m is slope, b is y-intercept
def compute_error_for_line_given_points(b, m, points):
totalError = 0
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
totalError += (y - (m * x + b)) ** 2
return totalError / float(len(points))
def step_gradient(b_current, m_current, points, learningRate):
b_gradient = 0
m_gradient = 0
N = float(len(points))
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
b_gradient += -(2/N) * (y - ((m_current * x) + b_current))
m_gradient += -(2/N) * x * (y - ((m_current * x) + b_current))
new_b = b_current - (learningRate * b_gradient)
new_m = m_current - (learningRate * m_gradient)
return [new_b, new_m]
def gradient_descent_runner(points, starting_b, starting_m, learning_rate, num_iterations):
b = starting_b
m = starting_m
for i in range(num_iterations):
b, m = step_gradient(b, m, array(points), learning_rate)
return [b, m]
def run():
points = genfromtxt("data.csv", delimiter=",")
learning_rate = 0.0001
initial_b = 0 # initial y-intercept guess
initial_m = 0 # initial slope guess
num_iterations = 1000000
print "Starting gradient descent at b = {0}, m = {1}, error = {2}".format(initial_b, initial_m, compute_error_for_line_given_points(initial_b, initial_m, points))
print "Running..."
[b, m] = gradient_descent_runner(points, initial_b, initial_m, learning_rate, num_iterations)
print "After {0} iterations b = {1}, m = {2}, error = {3}".format(num_iterations, b, m, compute_error_for_line_given_points(b, m, points))
if __name__ == '__main__':
run()
For Running this program you need Python and numpy should be installed.
Install Python :
Download (Install Python and set classpath/path)
Install Numpy :
Download (Ater installing python follow the below steps to install Numpy.)
1: go to this website to download correct package: http://sourceforge.net/projects/numpy/files/
2: unzip the package
3: go to the unzipped folder
4: open CMD here (path of the unzipped foolder)
5: then use this command to install numpy: " python setup.py install "
Note: Installing numpy will take more time like 10mins be patient.
After completing all the above steps , the only left is download the complete program , data.csv file from Github, then go to the download folder in cmd prompt and give command as
1: python gradient_descent_example.py
Please check the screen shots .
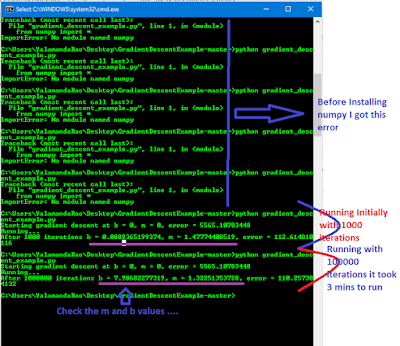 |
| Gradient Descent, Linear Regression and running the algorithm using python |
 |
| Installing Numpy |






